11.5. Classificação Supervisionada
Atualmente, métodos de aprendizado de máquina (machine learning) e de aprendizado profundo (deep learning) têm sido amplamente utilizados para classificar séries temporais de imagens e produzir mapas de uso e cobertura da terra com resultados promissores [125] [128] [129] [124] [107]. Esses métodos incluem Randon Forest, SVM (Support Vector Machine), TempCNN (Temporal Convolutional Neural Network) e TWDTW (Time-Weighted Dynamic Time Warping).
A maioria desses métodos utilizados são supervisionados, ou seja, eles possuem uma etapa de treinamento baseada em amostras previamente rotuladas, como ilustrado na Figura 11.20 . Essa etapa de treinamento tem como objetivo gerar um modelo capaz de prever a categoria ou a classe de novos dados não rotulados. Para gerar modelos assertivos, a etapa de treinamento necessita de amostras rotuladas de boa qualidade.
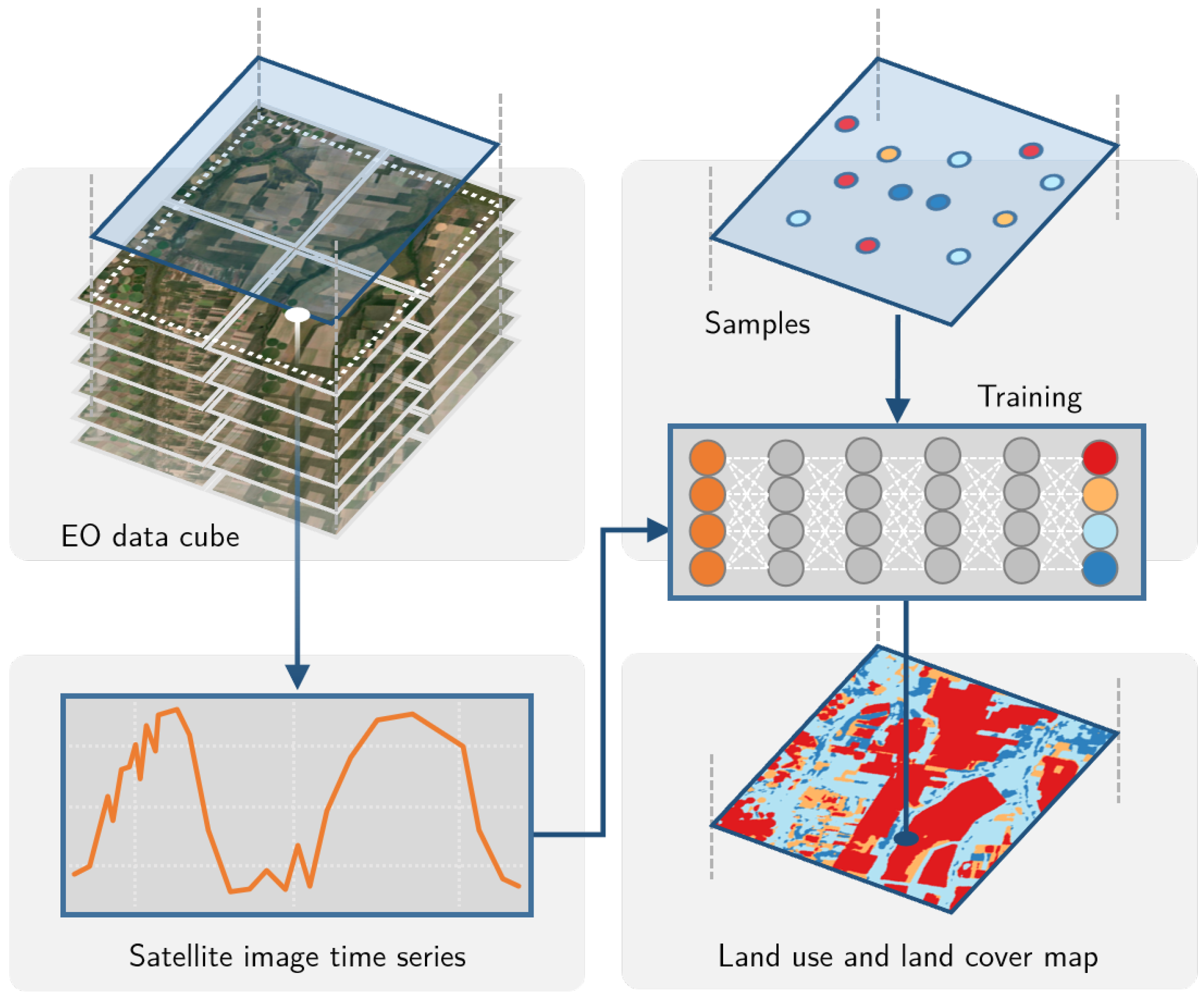
Figura 11.20 - Classificação supervisioanda de séries temporais de imagens de satélites para geração de mapas de uso e cobertura da terra. Fonte: [107]
Como ilustrado na Figura 11.20, cada amostra de treinamento é representada por uma classe de uso e cobertura da Terra, uma localização (longitude e latitude) e por um período da respectiva classe. A partir das informações das amostras, são recuperadas as séries temporais de imagens a partir de cubos de dados de observação da Terra. Cada série temporal de imagem é rotulada, ou seja, tem uma classe associada. A Figura 11.21 ilustra um conjunto de amostras de treinamento, suas localizações espaciais, suas séries temporais NDVI e suas classes de uso e cobertura da Terra. É importante notar que séries temporais de imagens NDVI associadas a diferentes classes de uso e cobertura da terra tem padrões distintos, como ilustrado na Figura 11.21 e nas Seções Séries Temporais de Imagens e Tipos de Uso e Cobertura da Terra e Séries Temporais de Imagens e Tipos de Agricultura . Essas séries são usadas então para treinar o classificador e gerar um modelo preditivo. Usando esse modelo, o método classifica todas as séries temporais do cubo de dados que não são rotuladas e, finalmente, gera um mapa de uso e cobertura da terra.
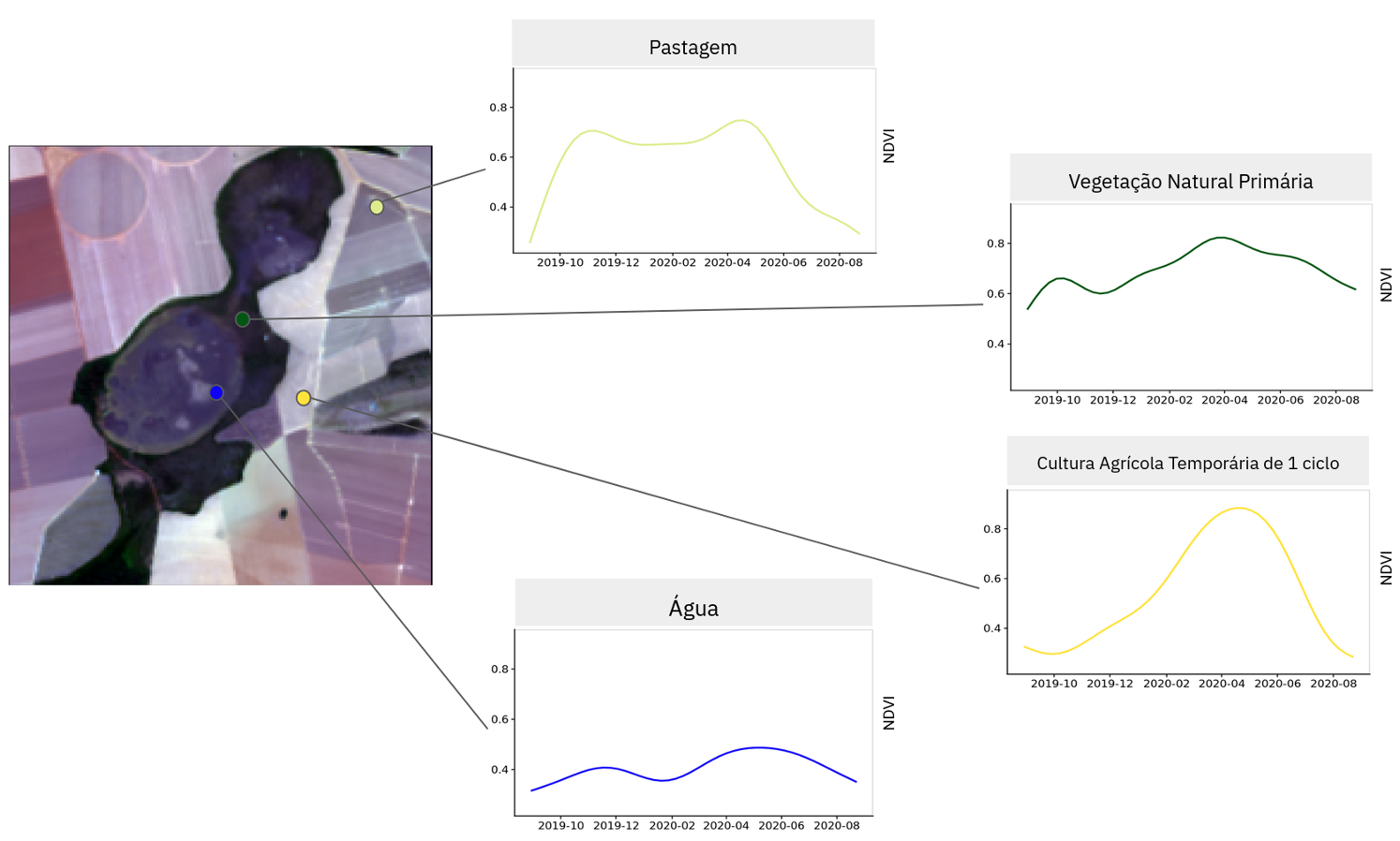
Figura 11.21 - Amostras de treinamento, suas localizações, suas séries temporais NDVI e suas classes.
O Pacote em R SITS (Satellite Image Time Series) implementa todo esse fluxo ilustrado na Figura 11.20: acesso à cubos de dados de observação da terra, extração de séries temporais de imagens a partir de amostras de treinamento, avaliação da qualidade das amostras de treinamento, treinamento de diferentes modelos de machine e deep learning, classificação de cubos de dados e realização de pós-processamentos para refinar o mapa gerado. Mais informações sobre esse pacote podem ser encontradas no SITS Book.
A qualidade das amostras de treinamento é crucial no processo de classificação. Amostras que são bem representativas das classes a serem identificadas resultam em boas classificações. Na classificação de uso e cobertura da terra, amostras de boa qualidade tem impacto direto na acurácia dos mapas gerados [128]. As amostras de treinamento devem descrever adequadamente a diversidade e a representatividade das classes de uso e cobertura da terra que devem ser identificadas pelo classificador. Além disso, essas amostras devem representar adequadamente a alta variabilidade das classes de uso e cobertura da terra em grandes áreas, capturando seus distintos padrões espaço-temporais [190].
Para analisar amostras de uso e cobertura da terra associadas a séries temporais de imagens, Santos et al. [197] propõem um método baseado na rede neural Self-Organizing Maps (SOM) e inferência bayesiana. SOM é uma técnica de cluster muito utilizada para agrupamento de séries temporais. O método proposto produz métricas que indicam a qualidade das amostras de uso e cobertura da terra, usando o SOM para gerar clusters ou agrupamentos de séries temporais de imagens e inferência bayesiana para avaliar as similaridades intra-cluster e inter-cluster [197].
A Figura 11.22 ilustra o método proposto por Santos et al. [197] para avaliação da qualidade das amostras de treinamento baseado no SOM. Nessa figura é possível observar que amostras de uma mesma classe de uso e cobertura da terra (soja-milho) que apresentam padrões diferentes, ou seja, séries temporais NDVI diferentes, são alocadas em neurônios distantes no mapa gerado pelo SOM. Ao plotar no espaço, é possível observar que essas amostras são de estados brasileiros distintos, que provavelmente tem calendários agrículos diferentes. Ao analisar a qualidade das amostras de treinamento, todas essas variações espaço-temporais das amostras de uso e cobertura da terra devem ser levadas em consideração e o método proposto por Santos et al. [197] auxilia os especialistas a fazerem essas avaliações.
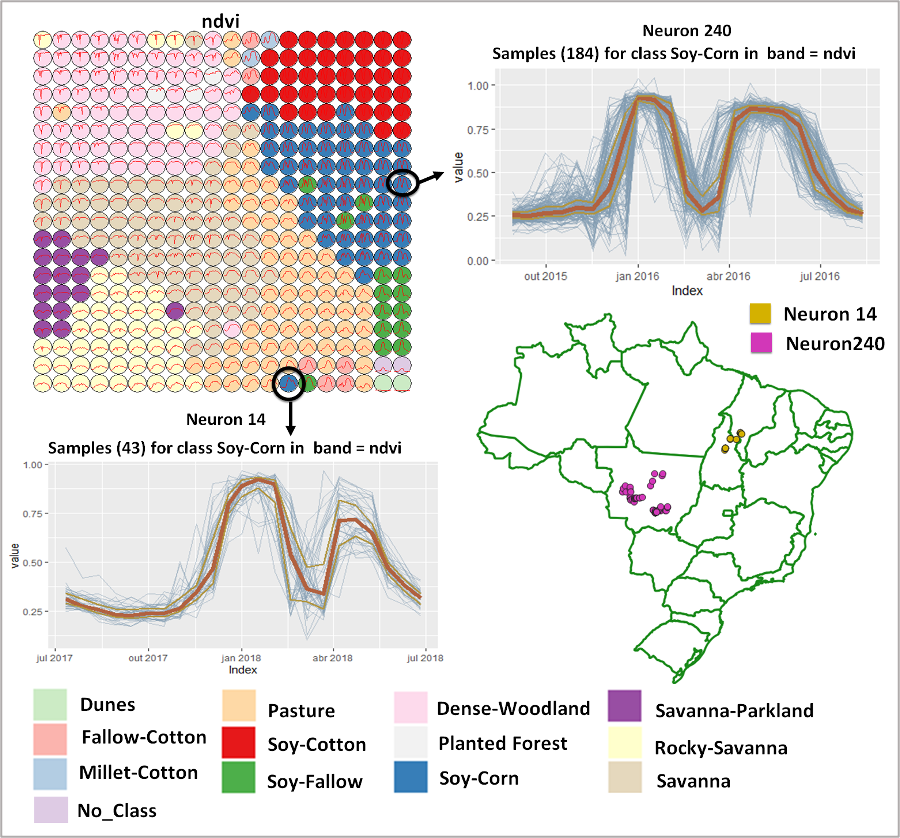
Figura 11.22 - Método para avaliação da qualidade de amostras de treinamento baseado no SOM. Fonte: [197]
Os mapas de uso e cobertura da terra lançados em agosto de 2024 pelo projeto TerraClass, para os biomas Cerrado e Amazônia, foram produzidos utilizando métodos de aprendizado de máquina e séries temporais de imagens, como descrito na Notícia de Lançamento do TerraClass. Esses mapas foram gerados utilizando a plataforma Brazil Data Cube, seus cubos de dados de imagens e pacote SITS (Satellite Image Time Series) [107].