1.8. Criando Tabelas
O comando SQL CREATE TABLE permite criar novas tabelas no banco de dados. A sintaxe básica desse comando é mostrada abaixo:
CREATE TABLE <nome-tabela>
(
<nome-coluna> <tipo-dados> [<restrição-coluna>]
[, <nome-coluna> <tipo-dados> [<restrição-coluna>] ]
[, <restrição-tabela> [, <restrição-tabela> ] ]
);
Onde:
nome-tabela: O nome de uma tabela deve começar por uma letra (a-z) ou pelo caracter sublinhado_, e os demais caracteres podem ser letras, dígitos (0-9) ou o caracter sublinhado_. Alguns exemplos de nomes válidos são:foco,foco_v2,estudante_disciplina,populacao_1940. Opcionalmente, o nome de uma tabela pode ser qualificado com o nome de um esquema. Neste caso usamos a sintaxenome-esquema.nome-tabela. Como exemplo de nomes de tabelas qualificados com o esquema, podemos citar:public.foco,geo.lote,ibge.populacao_brasil.Nota
Outro detalhe importante sobre o nome de tabelas consiste no uso de delimitadores com aspas duplas (
"). Neste caso, podemos criar identificadores contendo caracteres especiais, além de diferenciar letras maiúsculas e minúsculas. Exemplos:"Foco","Foco v2",ibge."População do Brasil".No entanto, esse recurso deve ser utilizado com moderação para não dificultar o uso dos identificadores na construção de consultas, uma vez que será necessário empregar os delimitadores (
").Nota
Os nomes de tabelas são limitados a no máximo 63 bytes. Logo, se usarmos apenas letras (
a-z), dígitos (0-9) ou sublinhado (_), isto significa um identificador de 63 caracteres.nome-coluna: O nome de colunas segue a mesma regra do nome de tabelas. A única diferença nesse caso é que não usamos a qualificação com o nome do esquema para colunas.tipo-dados: Podemos usar os tipos de dados discutidos nas Seções 1.5 e 1.6.restrição-coluna: É possível especificar restrições de integridade a serem mantidas pelo SGBD em relação ao valores da coluna. Os tipos mais comuns de restrições incluem:NOT NULL: Especifica que a coluna é obrigatória.NULL: Especifica que podemos armazenar valoresNULLna coluna.CHECK ( expressão ): Uma expressão lógica envolvendo o valor a ser inserido ou atualizado na coluna que deva ser avaliado como verdadeiro para que o valor seja considerado válido. Usaremos este tipo de restrição nas tabelas que criaremos nessa seção.DEFAULT expressão: Um valor padrão caso a coluna seja omitida nas inserções.GENERATED { ALWAYS | BY DEFAULT } AS IDENTITY: Será usado um valor gerado a partir de uma sequência autoincremental.UNIQUE: Indica que a coluna deverá ter valores únicos.PRIMARY KEY: Indica que a coluna é chave primária e, portanto, possui valores únicos.REFERENCES: Permite definir a coluna como uma chave estrangeira, referenciando a coluna de outra tabela.
restrição-tabela: Após as declarações das colunas, podemos incluir restrições que se aplicam à linha da tabela. Neste caso, podemos ter chaves primárias compostas, chaves estrangeiras compostas, chaves únicas compostas e retrições que envolvam valores de várias colunas. Portanto, podemos declarar as seguintes retrições:CHECK ( expressão ): Uma expressão lógica que deve ser avaliada como verdadeiro para que os valores sendo inseridos na linha sejam considerados válidos.UNIQUE: Lista de colunas que formam uma chave única composta.PRIMARY KEY: Lista de colunas que formam uma chave primária composta.FOREIGN KEY: Lista de colunas que formam uma chave estrangeira composta.
1.8.1. Exemplo Criação de Tabela
Vamos criar uma tabela de exemplo chamada sedes_municipais com a seguinte estrutura:
nome tabela: sedes_municipais |
||
|---|---|---|
colunas |
tipo de dados |
modificadores |
gid |
número inteiro |
chave primária |
nome |
texto de tamanho variável |
limitado a 50 caracteres |
localizacao |
geometria |
geometrias do subtipo ponto associados ao SRID 4326 |
O comando de criação dessa tabela é mostrado abaixo:
CREATE TABLE sedes_municipais
(
gid SERIAL PRIMARY KEY,
nome VARCHAR(50),
localizacao GEOMETRY(POINT, 4326)
);
Para inserir tuplas (linhas ou registros) na tabela sedes_municipais:
INSERT INTO sedes_municipais (nome, localizacao)
VALUES ('São Carlos', ST_GeomFromText('POINT(-47.88497 -22.02557)', 4326) ),
('Ouro Preto', ST_GeomFromText('POINT(-43.51592 -20.38144)', 4326) ),
('São José dos Campos', ST_GeomFromText('POINT(-45.90245 -23.20000)', 4326) );
Para consultar os metadados da tabela com feições denominada sedes_municipais:
SELECT * FROM geometry_columns WHERE f_table_name = 'sedes_municipais';
Exercício: Visualizar os dados da tabela sedes_municipais no QGIS.
1.8.2. Estudo de Caso
Considere o diagrama Entidade-Relacionamento (ER) mostrado na Figura 1.9.
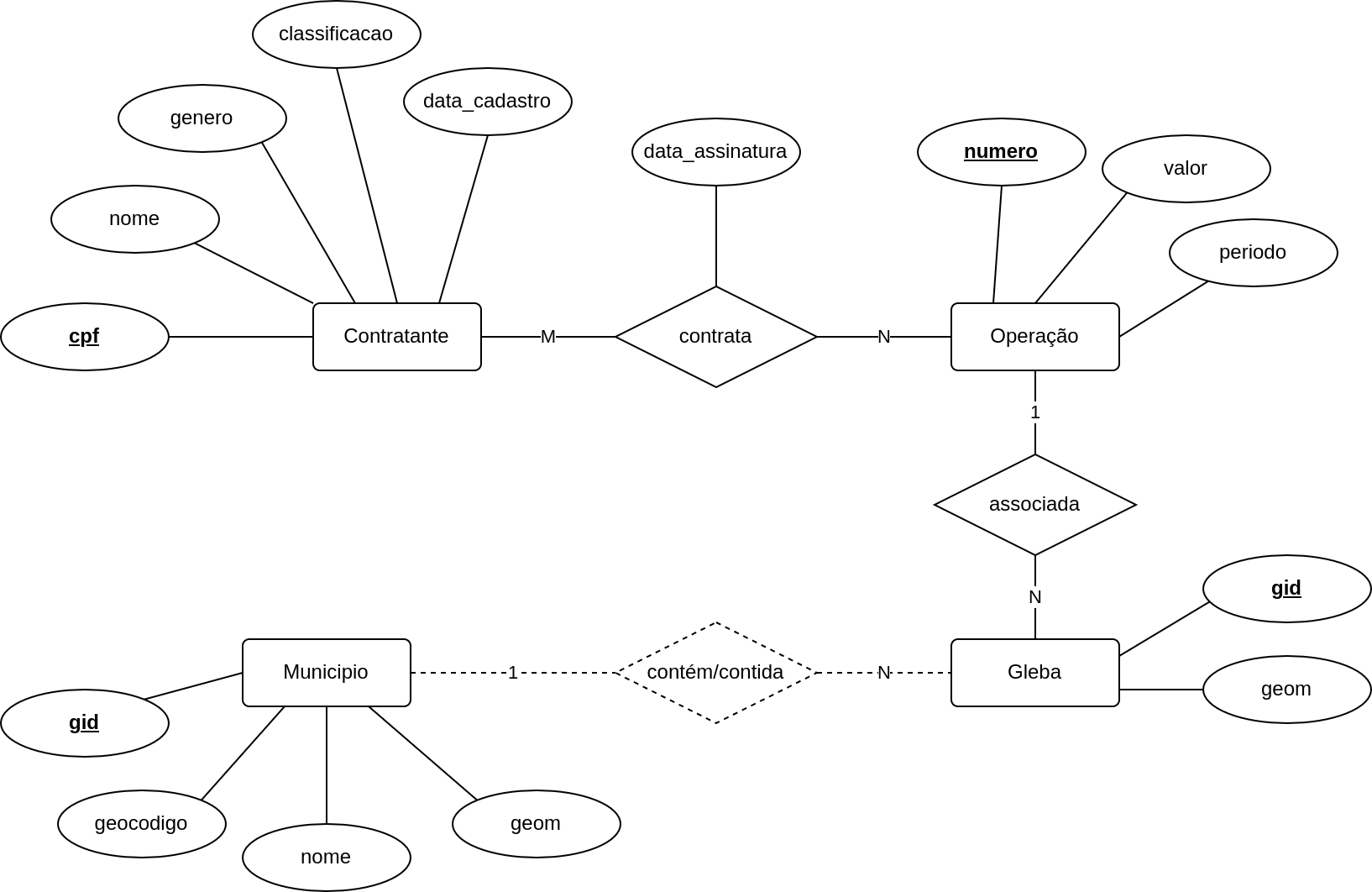
Figura 1.9 - Diagrama ER - Operações de crédito rural contratadas por pessoas físicas.
Nesse diagrama temos as seguintes informações:
Um Contratante possui propriedades como: CPF, nome, gênero, classificação ou porte do agricultor e a data de seu cadastro no banco de dados. O atributo destacado
cpfindica que os valores nessa coluna são únicos e, portanto, identifica unicamente um determinado contratante.Uma Operação, ou contrato de financiamento, possui propriedades como: número do contrato, valor do financiamento, o período do contrato (data de início e fim). O atributo destacado
numero_contratoindica que os valores nessa coluna são únicos e, portanto, identifica unicamente um determinado contrato.O relacionamento entre Contratante e Operação possui uma cardinalidade de
M:N(MparaN), isto é, um certo contratante pode contratar uma ou mais operações e uma operação pode estar associada a um ou mais contratantes. Além disso, esse relacionamento possui um atributo que corresponde à data de assinatura do contrato pelo contratante.Uma Gleba possui duas propriedades: identificador da gleba (
gid) e a geometria representando os limites da área da gleba.O relacionamento entre Operação e Gleba possui uma cardinalidade de
1:N(1paraN), isto é, um contrato pode referenciar uma ou mais glebas e uma gleba somente pode estar associada a um contrato.Um Município possui propriedades como: identificador (
gid), código do IBGE (geocodigo), nome e ogeometria representando os limites da área do município.O relacionamento entre Gleba e Município é um relacionamento espacial, indicado de “maneira informal” pelas linhas tracejadas.
Nota
A notação do Diagrama ER não permite representar relacionamentos espaciais. No exemplo acima, fizemos uma adaptação para ilustrar as informações que vamos manipular mais adiante.
A Figura 1.10 apresenta a cardinalidade envolvida nos relacionamentos do diagrama acima.
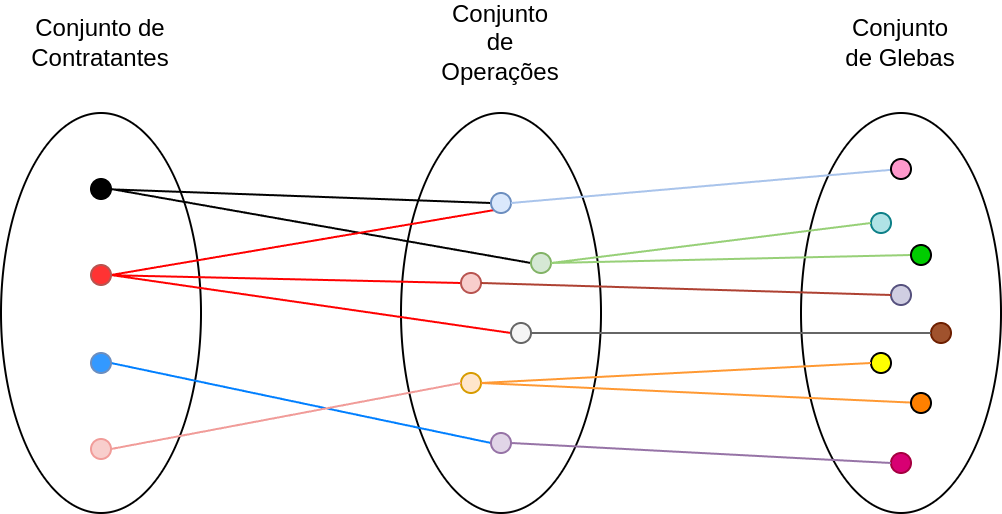
Figura 1.10 - Exemplo da cardinalidade dos relacionamento do Diagrama ER - Operações de crédito rural contratadas por pessoas físicas.
A partir da compreensão do diagrama ER, podemos criar um novo diagrama mais próximo da implementação que faremos no PostgreSQL. O diagrama mostrado na Figura 1.11 apresenta o modelo lógico que usaremos na criação das tabelas. Para cada entidade do diagrama ER da Figura 1.9, criamos uma relação ou tabela. Logo, as tabelas contratante, operacao, gleba e municipio no novo diagrama refletem esse processo. Os atributos darão origem às colunas nesse mapeamento, que já estarão associadas aos tipos de dados SQL suportados pelo PostgreSQL. Os atributos identificadores serão as chaves primárias, indicadas em negrito e com o símbolo PK. Nos relacionamentos 1:N, os identificadores do lado 1 são incluídos também na tabela do lado N para materializar o relacionamento entre as tabelas. Essa coluna que materializa o relacionamento é definida como uma chave estrangeira, indicada pelo símbolo FK. Esse processo ocorreu na tabela gleba, que agora possui a coluna operacao_numero como uma chave estrangeira, relacionando as linhas da tabela gleba com linhas da tabela operacao. Por último, os relacionamentos com cardinalidade M:N dão origem a novas tabelas, como o caso da tabela contratante_oeracao, com colunas formadas pelos identificadores das outras duas tabelas e mais o atributo do relacionamento.
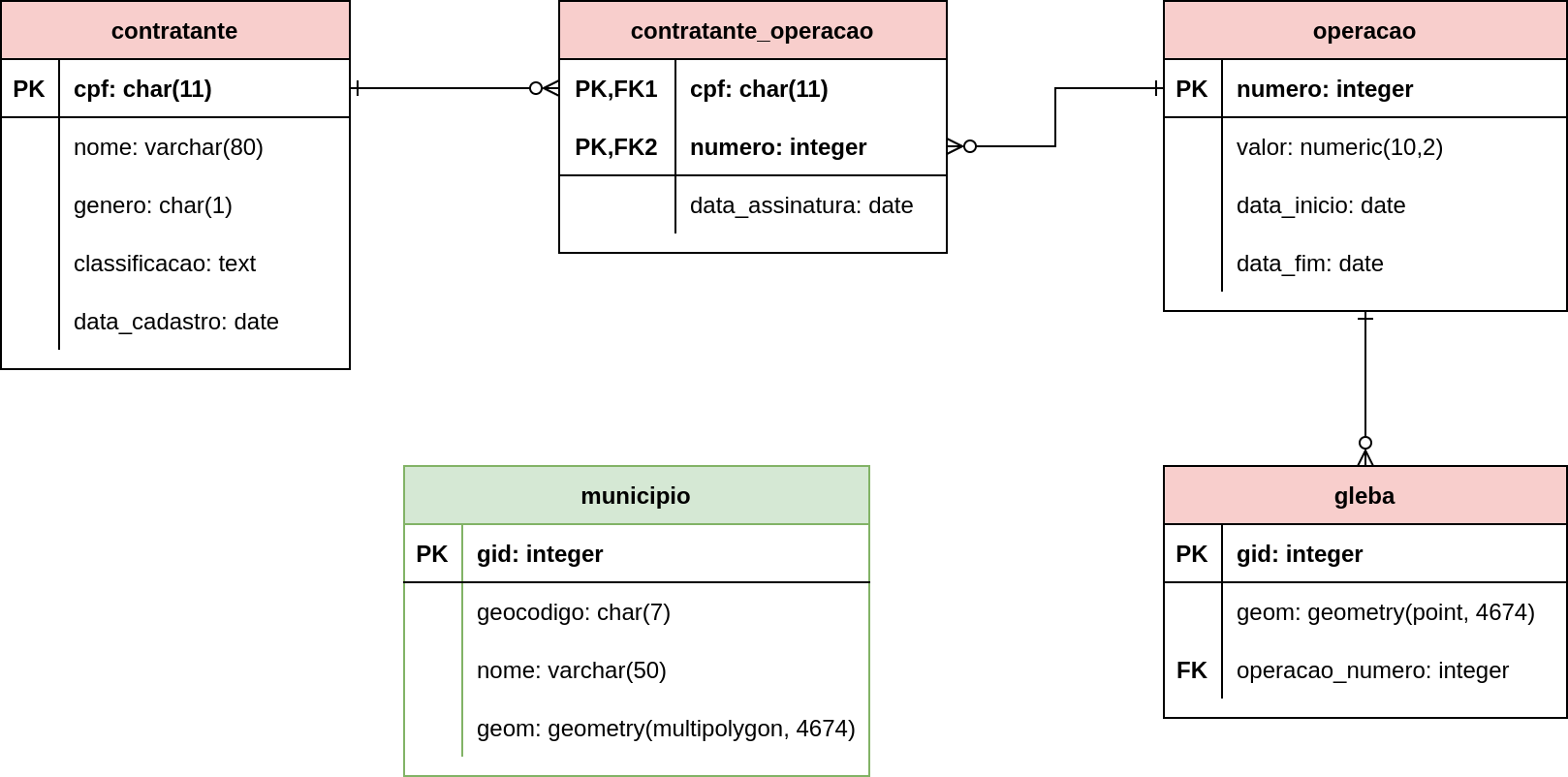
Figura 1.11 - Modelo lógico - Operações de crédito rural contratadas por pessoas físicas.
1.8.2.1. Comandos de Definição de Dados
Agora que temos o modelo das tabelas que queremos criar e sabemos a sintaxe básica do comando CREATE TABLE, vamos definir as tabelas contratante, contratante_operacao, operacao, gleba e municipio usando SQL.
Tabela: contratante:
CREATE TABLE contratante
(
cpf CHAR(11) PRIMARY KEY,
nome VARCHAR(80) NOT NULL,
genero CHAR(1) NOT NULL CHECK ( genero = 'm' OR genero = 'f' ),
classificacao VARCHAR(20) NOT NULL CHECK (classificacao IN ('pequeno produtor', 'médio produtor', 'grande produtor')),
data_cadastro DATE NOT NULL DEFAULT CURRENT_DATE
);
Na definição da tabela contratante temos:
A coluna
cpffoi definida como uma cadeia de caracteres de tamanho fixo (11) além de ser indicada como chave primária (PRIMARY KEY).A coluna
nomefoi definida como uma cadeia de caracteres de tamanho variável limitada a no máximo 80 caracteres, sendo os valores dessa coluna obrigatórios (NOT NULL).A coluna
generofoi definida como um caracter de tamanho 1, com uma restrição (check constraint) de uso apenas dos caracteresmouf.A coluna
data_cadastroterá o valor padrão da data corrente do sistema no caso de ser omitida na inserção.
Tabela: operacao
CREATE TABLE operacao
(
numero INTEGER PRIMARY KEY GENERATED ALWAYS AS IDENTITY,
valor NUMERIC(10,2) NOT NULL,
data_inicio DATE NOT NULL,
data_fim DATE NOT NULL
);
Na definição da tabela operacao temos:
A coluna
numerofoi definida como chave primária (PRIMARY KEY), comportando valores do tipo inteiro (INTEGER) gerados sequencialmente e automaticamente pelo servidor (GENERATED ALWAYS AS IDENTITY).A coluna
valorfoi definida como um número real de 10 dígitos com dois deles para casas decimais. Os valores dessa coluna são obrigatórios (NOT NULL).As colunas
data_inicioedata_fimforam definidas como datas e são campos obrigatórios.
Tabela: gleba
CREATE TABLE gleba
(
gid INTEGER PRIMARY KEY GENERATED ALWAYS AS IDENTITY,
geom GEOMETRY(MULTIPOLYGON, 4674) NOT NULL,
operacao_numero INTEGER NOT NULL REFERENCES operacao(numero)
ON DELETE NO ACTION
ON UPDATE CASCADE
);
Na definição da tabela gleba temos:
A coluna
gidfoi definida como chave primária (PRIMARY KEY), comportando valores do tipo inteiro (INTEGER) gerados sequencialmente e automaticamente pelo servidor (GENERATED ALWAYS AS IDENTITY).A coluna
geomfoi definida como um tipo geométrico, mais especificamente com o subtipo MultiPolygon com coordenadas associadas ao CRS EPSG:4674.A coluna
operacao_numerofoi definida como um tipo inteiro e obrigatório.Nessa tabela temos a definição de uma chave estrangeira, impondo um relacionamento de integridade referencial entre as tabelas
operacaoeglebanas colunasnumero(tabelaoperacao) eoperacao_numero(tabelagleba). A sentençaON DELETE NO ACTIONindica que no caso de remoção de linhas da tabelaoperacaoque tenham glebas associadas, deverá ser gerado um erro, impedindo a remoção das linhas da tabelaoperacao. A setençaON UPDATE CASCADEdefine que no caso de atualização da chave primária na tabelaoperacao, o novo valor deva ser propagado automaticamente para as linhas relacionadas na tabelagleba.
Nota
A definição de chave estrangeira pode ser indicada separadamente, como mostrado no exemplo abaixo:
CREATE TABLE gleba
(
gid INTEGER PRIMARY KEY GENERATED ALWAYS AS IDENTITY,
geom GEOMETRY(MULTIPOLYGON, 4674) NOT NULL,
operacao_numero INTEGER NOT NULL,
FOREIGN KEY (operacao_numero) REFERENCES operacao(numero)
ON DELETE NO ACTION
ON UPDATE CASCADE
);
Tabela: contratante_operacao
CREATE TABLE contratante_operacao
(
cpf CHAR(11) REFERENCES contratante(cpf)
ON DELETE NO ACTION
ON UPDATE CASCADE,
numero INTEGER REFERENCES operacao(numero)
ON DELETE NO ACTION
ON UPDATE CASCADE,
data_assinatura DATE NOT NULL DEFAULT CURRENT_DATE,
PRIMARY KEY (cpf, numero)
);
Repare na definição da tabela acima que:
A coluna
cpfpossui uma restrição de chave estrangeira, referenciando a colunacpfna tabelacontratante.A coluna
numerotambém possui uma restrição de chave estrangeira, referenciando a colunanumerona tabelaoperacao.A coluna
data_assinaturairá registrar a data em que o contratante assinou o contrato de financiamento.A chave primária dessa tabela é composta e, por isso, foi definida logo após a declaração de todas as colunas. Desta forma, podemos especificar as colunas
cpfenumerocomo a chave primária.
Tabela: municipio
CREATE TABLE municipio
(
gid INTEGER PRIMARY KEY GENERATED ALWAYS AS IDENTITY,
geocodigo CHAR(7) NOT NULL,
nome VARCHAR(50) NOT NULL,
geom GEOMETRY(MULTIPOLYGON, 4674) NOT NULL
);
Repare na definição da tabela acima que:
A coluna
gidfoi definida como chave primária (PRIMARY KEY), comportando valores do tipo inteiro (INTEGER) gerados sequencialmente e automaticamente pelo servidor (GENERATED ALWAYS AS IDENTITY).A coluna
geocodigofoi definida como uma cadeia de caracteres de tamanho fixo (7) e com valores obrigatórios (NOT NULL).A coluna
nomefoi definida como uma cadeia de caracteres de tamanho variável limitada a no máximo 50 caracteres, sendo os valores dessa coluna obrigatórios (NOT NULL).A coluna
geomfoi definida como um tipo geométrico, mais especificamente com o subtipo MultiPolygon com coordenadas associadas ao CRS EPSG:4674.O relacionamento espacial não será materializado em uma coluna pois iremos computar on-the-fly com os operadores topológicos suportados pelo PostGIS.